My entire time poking at the Framework Desktop machines I’ve been 100% focused on working on the AI/ML side of things, but with that and the weeks-longs inference sweeps mostly done atm (and media embargoes lifted), I started poking a little more on the CPU side of things, and was pretty surprised to find that it’s actually probably the fastest computer I have in my house right now. Here’s a quick Geekbench comparison against my EPYC 9274F workstation:
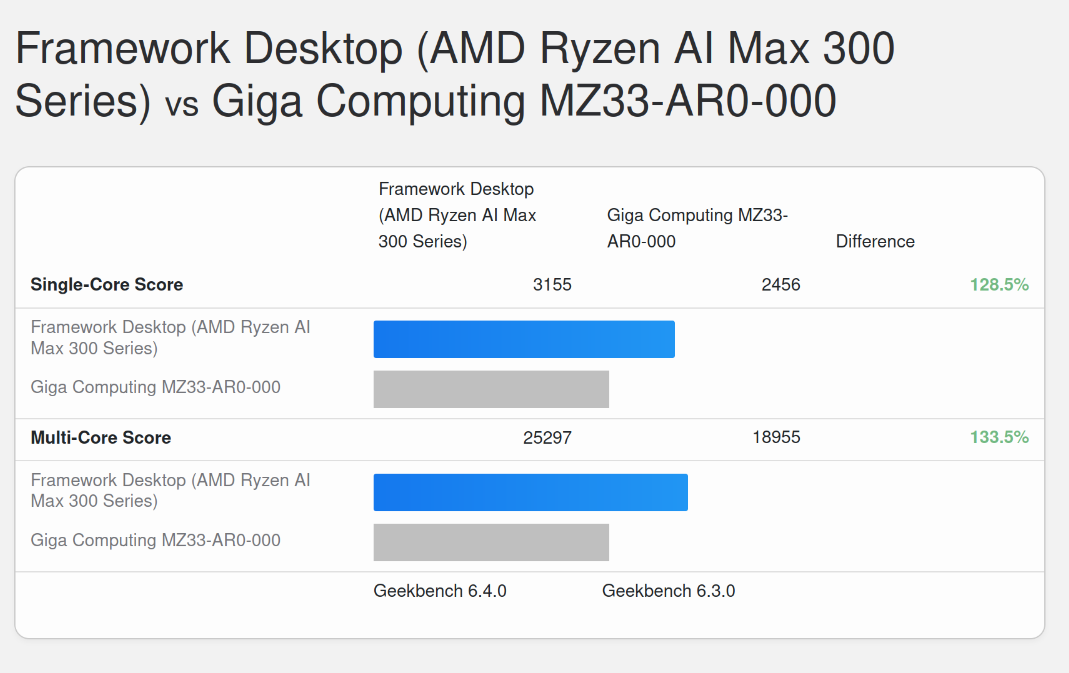
Pretty neat! I paid ~$2500 for my EPYC chip last year (also >$1K for the motherboard and almost $2K for the 384GB of memory). Granted that system has ECC, 128 lanes of PCIe 5.0 and a bunch of other fun stuff, but I think one of the things that’s easy to overlook when focused on the AI/LLM side of things is that the CPU is actually pretty great (and refreshingly, also just works).
I’m not sure if it’s been mentioned/pointed out btw, but while the GPU memory bandwidth is pretty close to what’s on the tin (I’ve gotten up to 221GB/s out of 256GB/s bus max), the CPU side is… much lower, about 85-125GB/s. For those interested in the numbers, I’ve run likwid, passmark, and intel-mlc: strix-halo-testing/hardware-test at main · lhl/strix-halo-testing · GitHub
FWIW, my EPYC system also gets much lower than theoretical MBW as well (theoretical max: 460.8 GB/s, actual, even with a full CCD/GMI links, different NUMA setups: 200-285GB/s). It still ends up about 2-3X higher than the Framework Desktop: speed-benchmarking/epyc-mbw-testing at main · AUGMXNT/speed-benchmarking · GitHub
One real-world CPU sanity check (building latest checkout of llama.cpp):
cmake -B build && cmake --build build --config Release -j$(nproc)
# EPYC 9274F
________________________________________________________
Executed in 58.34 secs fish external
usr time 263.81 secs 0.00 millis 263.81 secs
sys time 15.68 secs 2.46 millis 15.68 secs
# Framework Desktop
________________________________________________________
Executed in 50.20 secs fish external
usr time 253.12 secs 0.00 millis 253.12 secs
sys time 8.67 secs 1.22 millis 8.67 secs
The Framework Desktop is faster (also, sadly, the fan spins up louder), although not a completely fair test since I didn’t bother to close Firefox while running this particular test (actual benchmarks were of course from fresh boots with nothing else running).