The idea is to provide ready-to-use environments for LLM inference tailored at Strix Halo, together with configuration tips.
These all require you to install a recent Linux distribution, I recommend Fedora 42.
Llama.cpp Toolboxes
These are currently the best option for running many different LLMs on the Framework Desktop. You will see many toolboxes with different backends, right now I’d choose amdvlk or rocm-6.4.3-rocwmma. The repo has a link to a YouTube video that explains all the setup to get this going quickly.
vLLM Toolboxes / Container (WIP / EXPERIMENTAL)
This is still WIP and vLLM on Strix Halo is PITA at the moment, appreciate any contributions to support more models, right now this requires a lot of patching and still you can only run a subset of models.
I’ve been using your llama.cpp repo/Dockerfiles (specifically rocm-7rc-rocwmma with extra bits to build the RPC server) and it works really well. Thank you
Thank you for this perfect starting point! A silly question: you chose Fedora Workstation. Isn’t that also a full-fledged desktop environment (only with Gnome)? At this point, I tested it with the KDE Plasma desktop. Did I overlook something? Does it consume too many resources to fully utilize my 128 GB ?
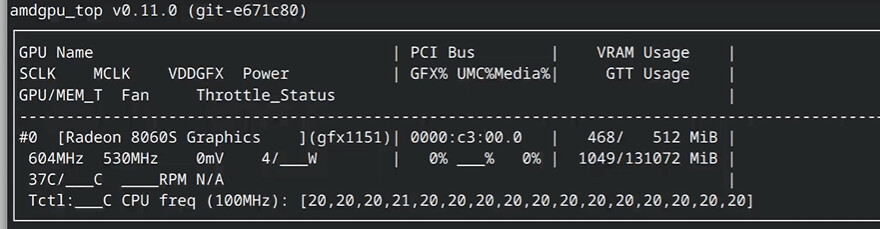
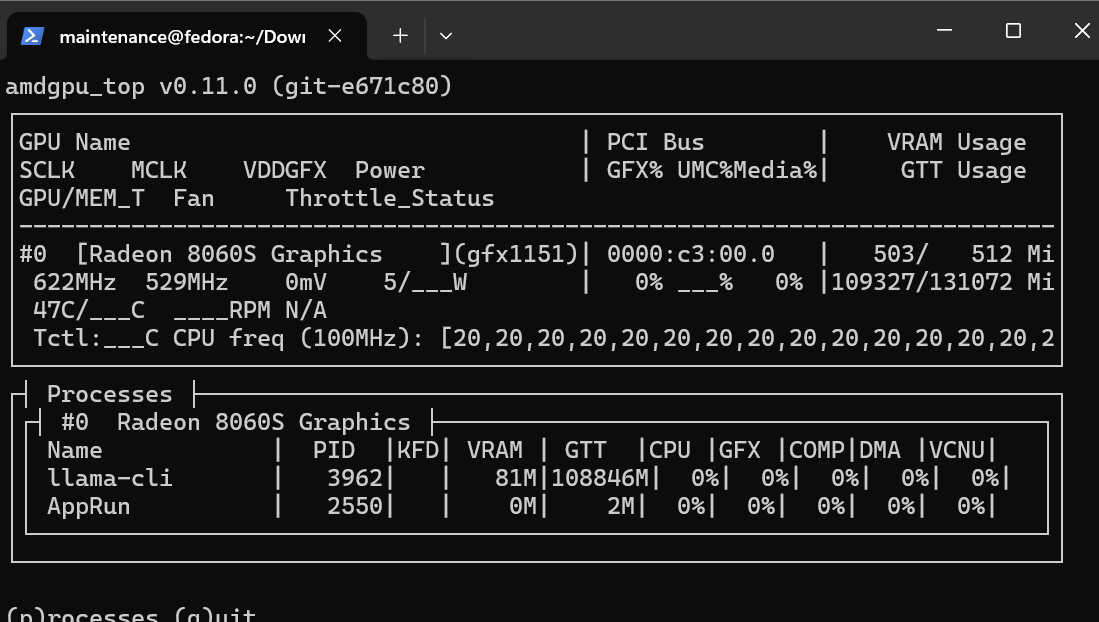
Have you actually tried to run large models? Sometimes the drivers report incorrect values with unified memory, worth just trying a large model and see how it goes first. If amdgpu_top reports the correct values, give it a go.
These are great, thanks for putting everything together.
I still think I have something wrong though as the output is ~12 tokens/sec with a model like gemma3-27B and around 5/sec with a larger model like Hermes-4-70B-Q4_K_M.
Is that normal? From looking at amdgpu_top I see the memory being correctly utilized and it is running on the GPU, so I think the Toolbox is setup right.
Currently running Bazzite, but I was getting the same perf on a Fedora 42 install.
Edit to note that I get about the same performance using the vulkan-radv and rocm-6.4.4 toolboxes.
I get worse rocm-6.4.4-rocwmma results but I think that is a Bazzite/ROCm issue. When I run the bench I get error/warnings:
rocBLAS error: No hipBLASLt solution found
This message will be only be displayed once, unless the ROCBLAS_VERBOSE_HIPBLASLT_ERROR environment variable is set.
rocBLAS warning: hipBlasLT failed, falling back to tensile.
This message will be only be displayed once, unless the ROCBLAS_VERBOSE_TENSILE_ERROR environment variable is set.
Same for me.
rocm-6.4.4 build for epel-9 did not look to have hipBLASLt config files for gfx1151.
It is OK for rocm-7.0.1 and 7.0.2 (new release today and recomanded)
I tried using the toolbox version on fc43 here is what I get
lama-cli -m models/qwen3-235B-A22B/Q3_K_M/Qwen3-235B-A22B-Instruct-2507-Q3_K_M-00001-of-00003.gguf -ngl 999 --no-mma
p
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = Radeon 8060S Graphics (RADV GFX1151) (radv) | uma: 1 | fp16: 1 | bf16: 0 | warp size: 64 | shared memory: 65536 | int do
t: 1 | matrix cores: KHR_coopmat
build: 6730 (e60f01d9) with cc (GCC) 15.2.1 20250924 (Red Hat 15.2.1-2) for x86_64-redhat-linux
main: llama backend init
main: load the model and apply lora adapter, if any
llama_model_load_from_file_impl: using device Vulkan0 (Radeon 8060S Graphics (RADV GFX1151)) (0000:c3:00.0) - 87086 MiB free
gguf_init_from_file: failed to open GGUF file ‘models/qwen3-235B-A22B/Q3_K_M/Qwen3-235B-A22B-Instruct-2507-Q3_K_M-00001-of-00003.gguf’
llama_model_load: error loading model: llama_model_loader: failed to load model from models/qwen3-235B-A22B/Q3_K_M/Qwen3-235B-A22B-Instru
ct-2507-Q3_K_M-00001-of-00003.gguf
llama_model_load_from_file_impl: failed to load model
common_init_from_params: failed to load model ‘models/qwen3-235B-A22B/Q3_K_M/Qwen3-235B-A22B-Instruct-2507-Q3_K_M-00001-of-00003.gguf’, t
ry reducing --n-gpu-layers if you’re running out of VRAM
main: error: unable to load model
⬢ [tmunn@toolbx ~]$ HF_HUB_ENABLE_HF_TRANSFER=1 hf download unsloth/Qwen3-235B-A22B-Instruct-2507-GGUF --include “Q3_K_M/*” --local-dir m
odels/qwen3-235B-A22B/
/home/tmunn/models/qwen3-235B-A22B
⬢ [tmunn@toolbx ~]$