Thank you very much @kyuz0 !
I miss something to fully see the whole resources.
Setup is done with:
sudo grubby --update-kernel=ALL --args=‘amd_iommu=off amdgpu.gttsize=131072 ttm.pages_limit=33554432
i also just reserved 512mb dedicated vram in bios.
but executing:
llama-cli --list-devices
shows only 86GB:
maintenance@fedora:~$ toolbox enter llama-vulkan-radv
⬢ [maintenance@toolbx ~]$ llama-cli --list-devices
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = Radeon 8060S Graphics (RADV GFX1151) (radv) | uma: 1 | fp16: 1 | bf16: 0 | warp size: 64 | shared memory: 65536 | int dot: 1 | matrix cores: KHR_coopmat
Available devices:
Vulkan0: Radeon 8060S Graphics (RADV GFX1151) (87722 MiB, 86599 MiB free)
amdgpu_top:
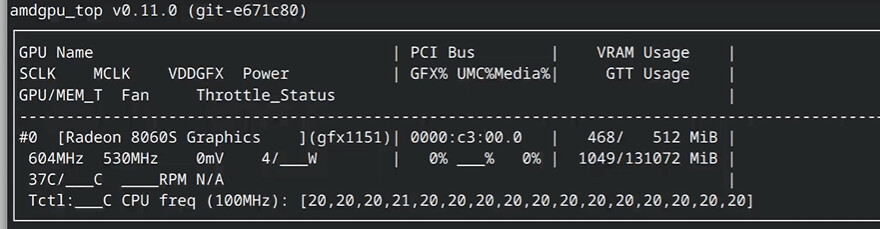
some little tiny bit is missing …
Because i see the same resources in LM Studio (84GB as example)
means has nothing to do with the setup toolbox or LM Studio.
Fedora 42 specific ? O.o
KR Lars