Hey someone on GitHub linked my this post and i thought i want to share some things to make this more accessible to everyone.
My Wish-Setup was:
Proxmox9 with LXCs that all can use LLMs via Docker and use AMD AI 300 Series APUs for giant LLMs but less fast responses and also a mixed-in RTX2000E for lower-weights but fast response LLMs models. Big requirement was “no exclusivity to one VM” also not weird VBios and Reset-Hang-Host-Reboots. As there was nothing to find for this or compare against, i had to figure it out myself over like 3-4 weeks in my free-time and im happy to report that i solved this and fully-automated it to share it with everyone on the web. Took some time though ![]()
![]() .
.
Here is what i got, feel free to test it or improve it with me.
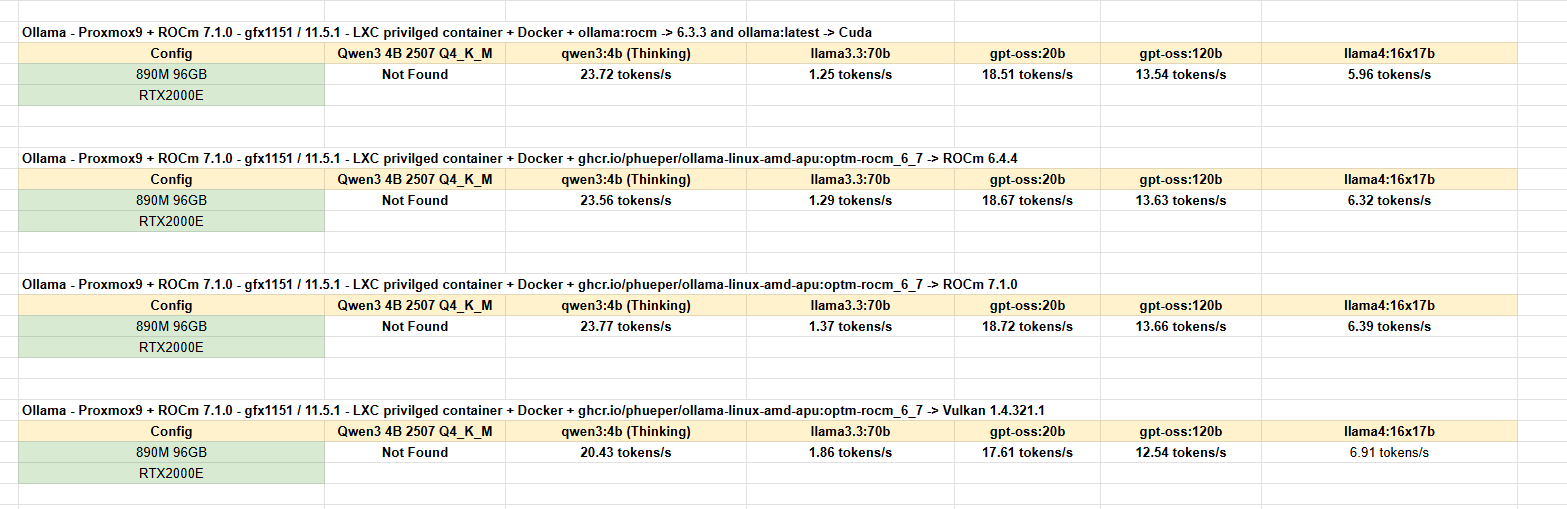
I currently have for testing 5 LXCs with AMD APU and 3 LXCs with Nvidia running, all transparent to the Host with any process. Every LXC container has Docker-installed and a ollama:latest or ollama:rocm or this persons image version running which supports ROCm 6+7+Vulkan:
Here are some performance benchmarks if you like to read those: