-
Which Linux distro are you using?
Archlinux -
Which release version?
(if rolling release without a release version, skip this question)
(If rolling release, last date updated?)
Freshly installed -
Which kernel are you using?
uname -a
Linux frmw13 6.15.3-arch1-1 #1 SMP PREEMPT_DYNAMIC Thu, 19 Jun 2025 14:41:19 +0000 x86_64 GNU/Linux -
Which BIOS version are you using?
dmidecode -s bios-version
03.03 -
Which Framework Laptop 13 model are you using? (AMD Ryzen™ AI 300 Series, AMD Ryzen™ 7040 Series, Intel® Core™ Ultra Series 1, 13th Gen Intel® Core™ , 12th Gen Intel® Core™, 11th Gen Intel® Core™)
AMD Ryzen™ AI 300 Series
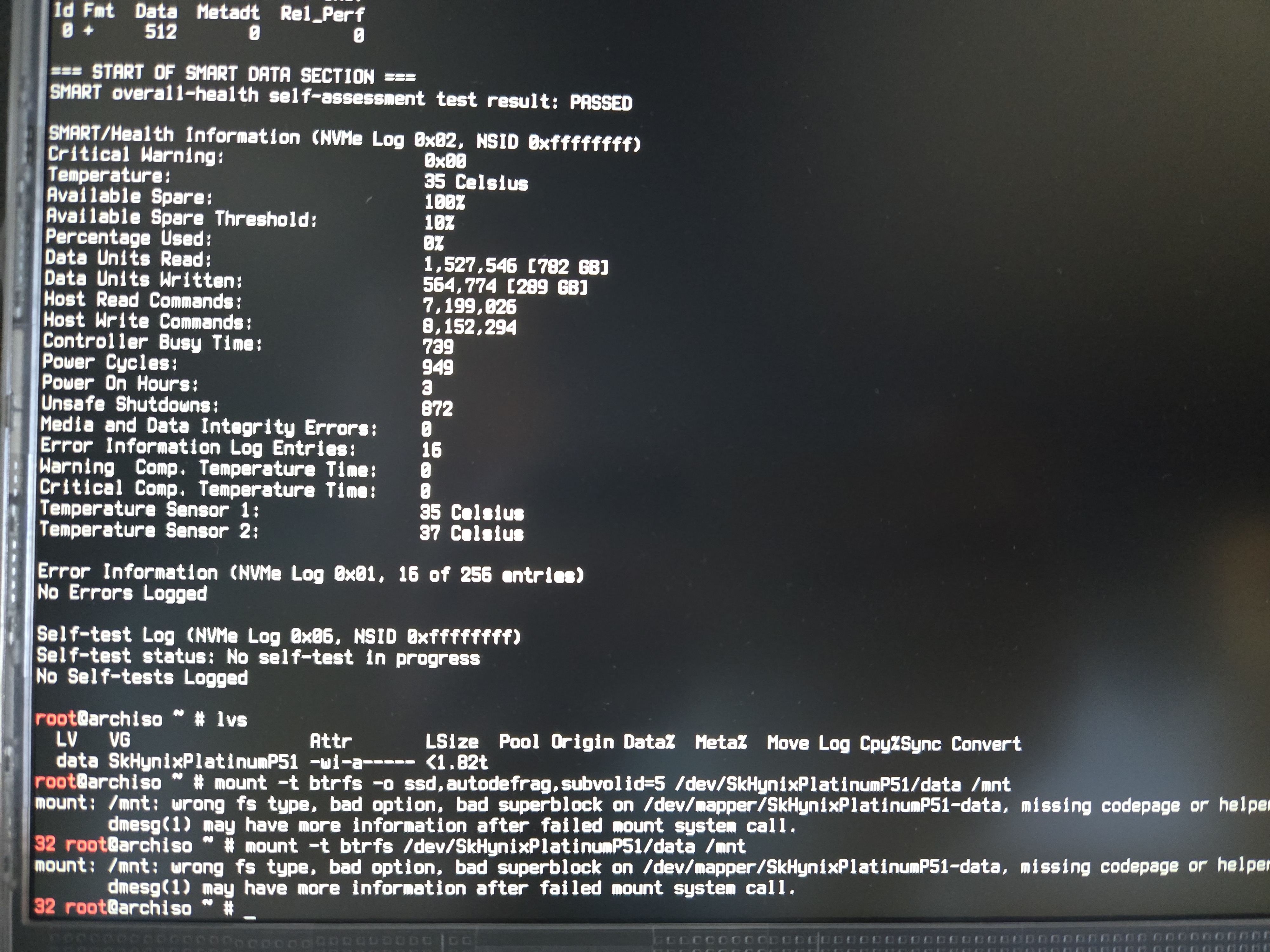
SSD is “SHPP51-2000GM”, SK Hynix Platinum P51, firmware version 61060A50. I’m experiencing exceedingly high power cycles/unsafe shutdowns during s2idle: slept for like 2 whole days, and the count sky-rocketed to 436 power cycles and 416 unsafe shutdowns. I’m pretty sure they were both zero in the beginning: smartctl is one of the first commands I issue when I’m playing with new hardware.
At first I thought it was probably the bios AMD PSPP playing badly with the SSD, so I tried turning it off: it was on when I discovered the issue, probably since I messed around the bios when I got my hand on the machine before installing the OS, thus the following observation is when it’s off i.e. no downgrade, only to no avail: I put the laptop into sleep again for like 4 more hours, and power cycle incremented by 3, unsafe shutdown incremented by 4.
Kernel log doesn’t seem to suggest anything too interesting:
journalctl -o short-precise -k -b -1 | grep -i nvme
Jun 22 14:23:10.667075 archlinux kernel: nvme 0000:bf:00.0: platform quirk: setting simple suspend
Jun 22 14:23:10.667284 archlinux kernel: nvme nvme0: pci function 0000:bf:00.0
Jun 22 14:23:10.691053 archlinux kernel: nvme nvme0: 16/0/0 default/read/poll queues
Jun 22 14:23:10.693042 archlinux kernel: nvme0n1: p1 p2
Jun 22 14:23:18.477043 frmw13 kernel: nvme nvme0: using unchecked data buffer
Jun 22 14:23:18.479044 frmw13 kernel: block nvme0n1: No UUID available providing old NGUID
Jun 22 14:51:36.188976 frmw13 kernel: nvme nvme0: 16/0/0 default/read/poll queues
Jun 22 14:52:47.632912 frmw13 kernel: nvme nvme0: 16/0/0 default/read/poll queues
Jun 22 15:28:25.492790 frmw13 kernel: nvme nvme0: 16/0/0 default/read/poll queues
Jun 22 17:19:08.510854 frmw13 kernel: nvme nvme0: 16/0/0 default/read/poll queues
Jun 22 19:04:35.519197 frmw13 kernel: nvme nvme0: 16/0/0 default/read/poll queues
Jun 22 22:55:30.540449 frmw13 kernel: nvme nvme0: 16/0/0 default/read/poll queues
I’ve read that some SSDs has trouble waking up after entering certain power states as suggest in Arch Wiki; not that the symptoms are the same, since no system freezes besides smartctl reporting concerning numbers, nevertheless I decided to give it a try: maybe it’s since the deepest power state of SK Hynix P51 is somewhat buggy on AMD motherboards? So just before posting here, I rebooted with new kernel parameter. Interestingly rebooting the computer does not lead to changes of these two fields, nor does it change when I’m actually using the laptop.
journalctl -o short-precise -k -b 0 | grep -i nvme
Jun 22 23:11:06.635519 archlinux kernel: Command line: ro root=/dev/SkHynixPlatinumP51/data add_efi_memmap rootflags=rw,relatime,ssd,subvol=/@root quite loglevel=3 nmi_watchdog=0 nvme_core.default_ps_max_latency_us=3200 initrd=initramfs-linux.img
Jun 22 23:11:06.636472 archlinux kernel: Kernel command line: ro root=/dev/SkHynixPlatinumP51/data add_efi_memmap rootflags=rw,relatime,ssd,subvol=/@root quite loglevel=3 nmi_watchdog=0 nvme_core.default_ps_max_latency_us=3200 initrd=initramfs-linux.img
Jun 22 23:11:06.701075 archlinux kernel: nvme 0000:bf:00.0: platform quirk: setting simple suspend
Jun 22 23:11:06.701300 archlinux kernel: nvme nvme0: pci function 0000:bf:00.0
Jun 22 23:11:06.726032 archlinux kernel: nvme nvme0: 16/0/0 default/read/poll queues
Jun 22 23:11:06.728015 archlinux kernel: nvme0n1: p1 p2
Jun 22 23:12:28.976020 frmw13 kernel: nvme nvme0: using unchecked data buffer
Jun 22 23:12:28.977009 frmw13 kernel: block nvme0n1: No UUID available providing old NGUID
cat /sys/module/nvme_core/parameters/default_ps_max_latency_us
3200
The 3200 comes from the smartctl power state Ex_Lat (I gave it some margins to try to ensure it can reach power state 3, 0.05w seemed good enough if it mitigates the issue, but I haven’t really have time to dig into the kernel source to see if this settings is sane):
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 10.50W - - 0 0 0 0 305 675
1 + 6.5000W - - 1 1 1 1 330 700
2 + 2.0000W - - 2 2 2 2 400 870
3 - 0.0500W - - 3 3 3 3 2000 3000
4 - 0.0035W - - 4 4 4 4 2000 12000
I’m putting the laptop to sleep right now and will update the results tomorrow, hoping this would be a valid workaround. Again, this experiment is conducted when bios AMD PCIe automatic downgrade to 3.0 already turned off.
If anyone knows how to circumvent the issue, please share your knowledge. I really hope my laptop doesn’t just cook my shiny PCIe 5.0 SSD just by s2idle for prolonged amount of time.